
FAIR studies competitive programming as a sociotechnical ecosystem under LLM disruption, rather than only as a model benchmark problem. The paper integrates 37 cross-role interviews, a global survey of 207 contestants, and large-scale Codeforces trace analysis to examine three coupled questions: workflow transformation, fairness boundaries, and governance adaptation.
The core finding is a persistent gap between policy acceptance and enforcement confidence: communities largely agree on anti-cheating norms, but remain uncertain about enforceable boundaries and reliable detection in real-world contest settings.
RQ1 (Workflow): How LLMs reshape the practices of contestants, problem setters, coaches, and platform stewards.
RQ2 (Fairness): How communities draw boundaries between acceptable assistance and misconduct.
RQ3 (Governance): How rules, detection, and accountability mechanisms co-evolve under AI pressure.
FAIR contributes: (1) cross-role empirical evidence of workflow restructuring, (2) a gray-zone map of contested fairness norms, and (3) a layered, chess-inspired governance agenda for AI-era contests.
Interviews: 37 participants across four roles (contestants, setters, coaches, stewards), from novices to ICPC/IOI-level experts.
Survey: 207 valid global responses, with reliability checks (Cronbach's alpha = 0.76, KMO = 0.80, Bartlett p < .001).
Platform traces: 336 rated Codeforces contests (2022-2025), 4,844,702 participations, and 64,277,033 submissions.
This triangulation links perception-level evidence (interviews/survey) with behavior-level evidence (platform logs), enabling stronger conclusions than single-source analyses.

Global survey coverage of 207 respondents across major competitive programming regions.
This work shows that LLMs are reshaping competitive programming through a division-of-labor pattern rather than full automation, while the most acute conflict concentrates on fairness and governance in online contests.
Through cross-role triangulation (interviews with contestants, setters, coaches, and stewards, plus survey and log evidence), we find that contestants rarely depend on LLMs before contests and largely avoid them during contests, with strong consensus that in-contest AI use is cheating/unfair. In contrast, they heavily use LLMs in post-contest review and daily training for upsolving, hint-seeking, explanation, and reducing boilerplate burden.
A clear skill gradient appears: novices are more likely to treat LLMs as accelerators, while high-rated contestants are more restrained and selective.
Problem setters integrate LLMs into low-creativity stages (generator/stress-test scripting, multilingual translation, statement polishing, and pre-contest AI-as-solver checks), but broadly reject AI involvement in original idea generation.
Coaches report limited change in core teaching flow; most change happens in screening and handling AI dependence or integrity risks. Platform stewards report a workload shift toward monitoring, review, and report handling.
Overall, LLM adoption is expanding, but role boundaries remain actively negotiated and institutionally constrained.
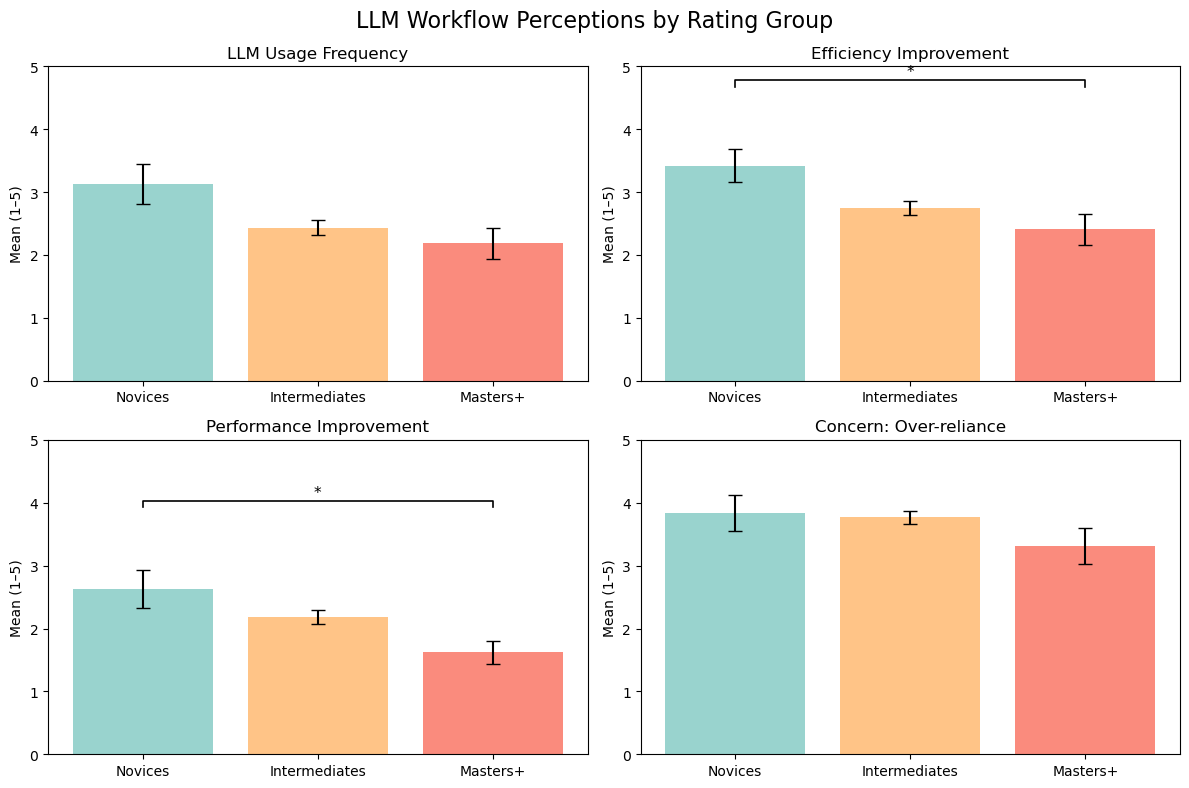
Novices perceive stronger efficiency/performance improvement, while over-reliance concern remains high across rating groups.

Workflow restructuring in problem setting: selective LLM integration in low-creativity stages, human control in core design stages.
The fairness boundary is not binary. Translation and lightweight completion are often tolerated, while conceptual hint outsourcing and pre-submission AI checking are widely rejected.
The data also reveals a hidden undercurrent: batch prompt-feeding of problem statements, output laundering/rewriting, and encrypted-group redistribution of AI-generated content.
These covert pipelines help explain why formal rules can appear strict while practical enforcement remains difficult, especially when misconduct is partially externalized off platform.
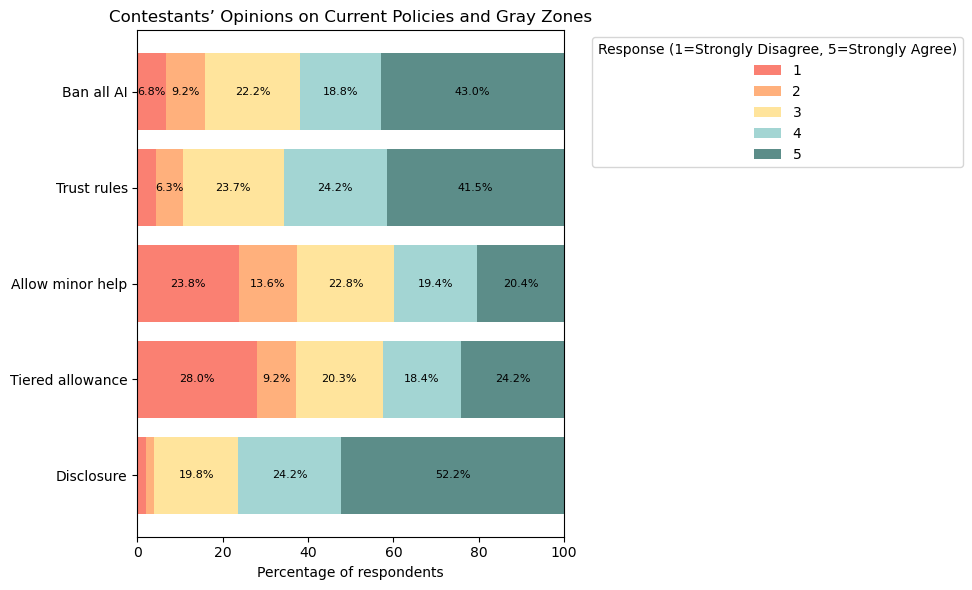
Policy attitudes show a clear anti-cheating baseline with persistent disagreement in bounded-assistance scenarios.
A core paradox emerges: participants are broadly willing to follow AI rules, but are less confident those rules can be enforced fairly and consistently.
This trust gap is reinforced by the mismatch between visible penalties and latent behavior shifts suggested by workflow and platform evidence.
In short, community legitimacy now depends not only on rule clarity, but on believable enforcement pathways under inevitable uncertainty.
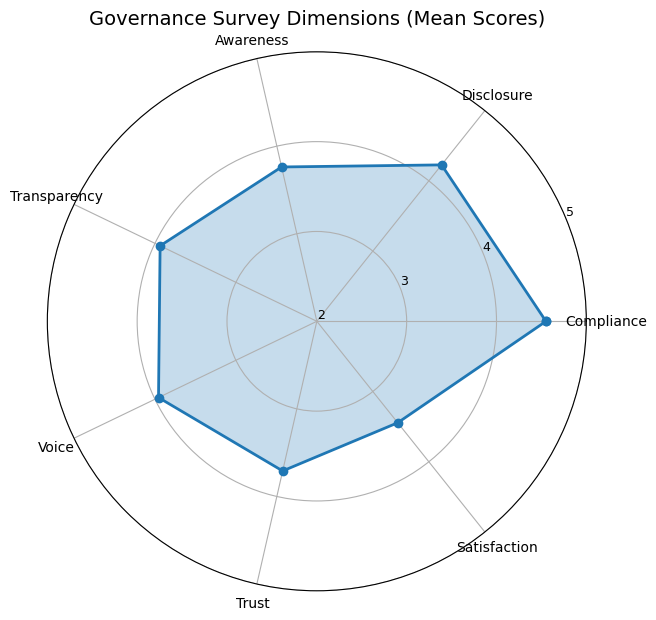
The radar chart shows the compliance-trust gap: support for rules is stronger than confidence in enforceability.
The novelty of FAIR is not another "can the model solve problems" benchmark. Instead, it treats competitive programming as a high-intensity institutional arena of human-AI interaction, and uses a cross-role evidence chain to explain whose work changes, where boundary disputes emerge, and why governance becomes hard. By combining interviews, a global survey, and platform logs from 2022-2025, the paper further shows that official penalty records alone are insufficient to characterize real ecosystem change.
Building on this diagnosis, FAIR proposes a chess-inspired layered governance framework: near-real-time checks and audits, peer co-monitoring/reporting mechanisms, cross-validation with offline performance and historical trajectories, plus expert review with procedural justice. Under realistic constraints (very low tolerance for false accusations, yet inevitable missed detections), this framework aims to maximize contest credibility. This is crucial for platforms, schools, and organizers that use competitive programming for education and talent selection, and offers transferable governance strategies for broader online assessment and competition-based learning systems.
The paper notes sample imbalance, role-coverage constraints, social-desirability bias in self-report data, and imperfect proxy validity in platform-level indicators.
Future work should extend underrepresented populations, add longitudinal and ethnographic evidence, and improve detection-evaluation pipelines that separate ecosystem drift from AI-specific effects.






